Le processeur vectoriel configurable permet des performances évolutives dépassant n'importe quel autre cœur IP.
Andes annonce aujourd'hui les processeurs AndesCore ™ 27 et les présentera au RISC-V Summit. La série 27 est le premier cœur RISC-V sous licence à fournir à un détenteur de licence de production l’extension d’instruction vectorielle RISC-V (RVV) et à préserver la bande passante et l’efficacité de la mémoire. Andes a également restructuré son sous-système de mémoire. La première livraison du noyau de processeur a été achevée au premier détenteur de licence Andes, et la sortie de la production est prévue pour le premier trimestre 2020. Dr Charlie Su, directeur technique d'Andes Technology et EVP dévoilera les détails de ce produit novateur au Sommet.
L'avènement de l'IA, de l'AR / VR, de la vision par ordinateur, de la cryptographie et du traitement multimédia nécessite un calcul complexe de gros volumes de données matricielles. Contrairement à la technologie SIMD avancée des autres fournisseurs, qui offre une plage de performances étroite dictée par le contrôle de leur architecture, la spécification RVV envisage un jeu d’instructions puissant avec des tailles de données évolutives, des implémentations de microarchitecture flexibles et des décisions du sous-système de mémoire permettant une optimisation au niveau système. Avec les cœurs de processeur de la série 27, Andes offre ces performances et cette flexibilité sans précédent à la communauté RISC-V et permet pour la première fois aux cœurs RISC-V de combler le vide d'applications que même d'autres fournisseurs n'ont pas pu atteindre.
"La série 27 marque une nouvelle étape importante dans le voyage Andes et RISC-V, et je ne pourrais être plus fier de notre équipe de R & D pour cet exploit", a déclaré Frankwell Lin, président d'Andes. «L’extension RVV propulse RISC-V au-delà de toute technologie centrale de processeur sous licence dans les marchés les plus en vogue, et la confiance de notre titulaire dans l’équipe de R & D permet à Andes d’être le premier à concrétiser cette vision ambitieuse. L'équipe a travaillé ensemble depuis la spécification jusqu'à la livraison en moins de neuf mois. C’est l’un des voyages les plus passionnants de l’histoire des Andes. "
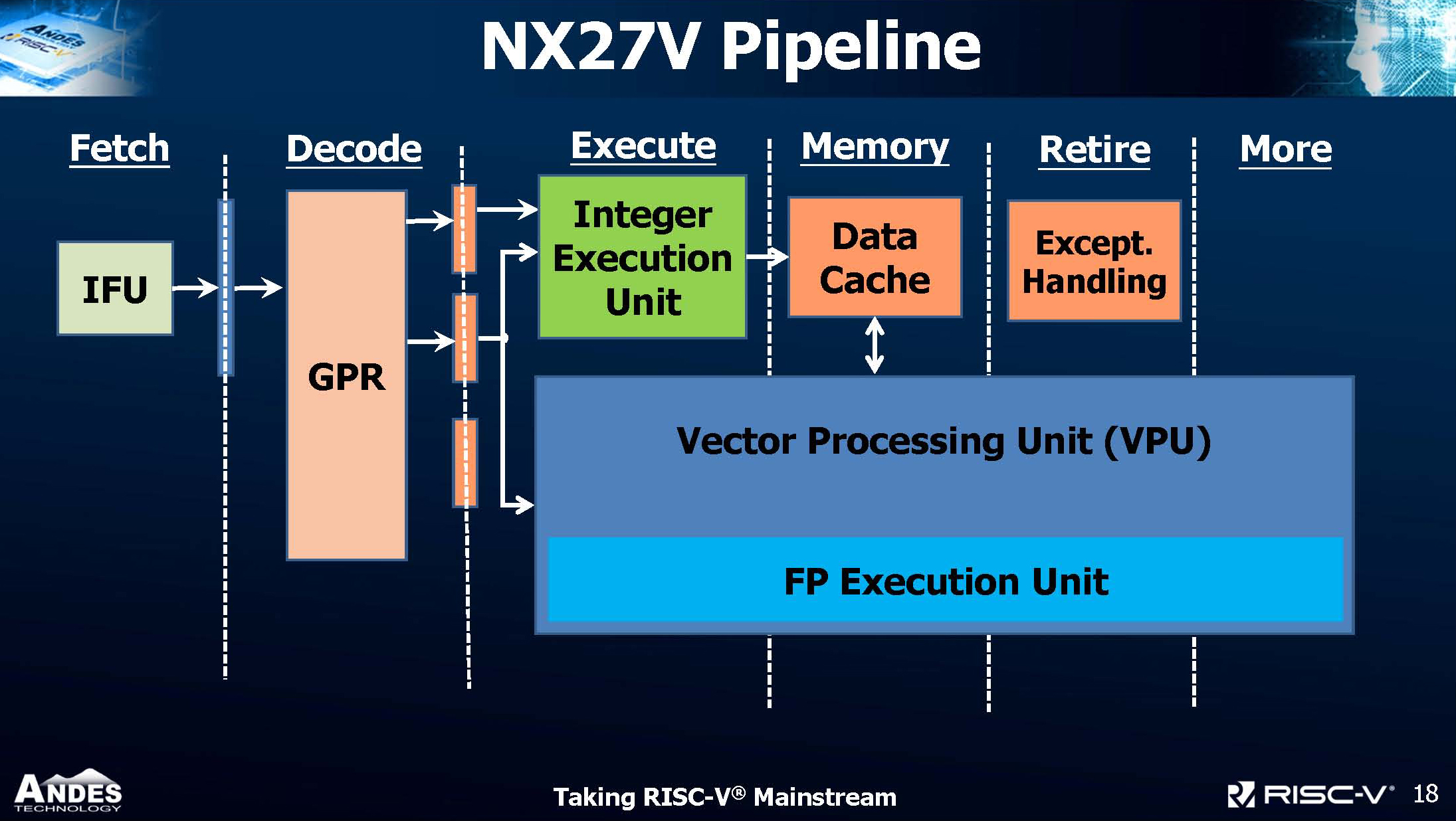
Les séries 27 au départ seront les A27 32 bits, ainsi que les AX27 et NX27V 64 bits. Ils bénéficient des cœurs de la série 25 éprouvés des Andes, qui prennent en charge les dernières spécifications RISC-V, les composants au niveau des sous-systèmes, ainsi que l’activation des écosystèmes grâce aux 14 années de développement de la R & D d’Andes. Les A27 et AX27, conçus pour les applications fonctionnant sous Linux, offrent une bande passante mémoire 50% supérieure à celle de ses prédécesseurs de la série 25. Le NX27V contient une unité de traitement de vecteur (VPU) qui prend en charge le jeu d’instructions vectorielles évolutif RVV, conçu dès le départ pour être une unité de calcul à vectorisation complète semblable à Cray à la croissance incrémentale à partir des instructions SIMD à partir de laquelle certains SIMD avancés ont évolué. En tant que tel, il existe un fichier de registre de vecteurs (VRF) complet comprenant un nombre d'éléments configurable par l'utilisateur par registre. Chaque vecteur peut avoir une longueur arbitraire allant de 64 bits à 512 bits (VLEN) et jusqu'à 4096 bits en combinant jusqu'à huit registres de vecteurs (LMUL). Il permet également à chaque calcul d'entiers, de points fixes, de nombres à virgule flottante et d'autres représentations optimisées pour l'intelligence artificielle d'avoir une largeur de bit comprise entre 4 et 32 bits (SEW) et de gérer les derniers éléments de matrice non divisibles dans la même boucle. La VPU série 27 implémente toutes ces fonctionnalités et dispose de plusieurs unités fonctionnelles pouvant être chaînées. Chacune peut fonctionner dans des pipelines indépendants pour maintenir les débits de calcul nécessaires aux fonctions critiques du noyau. Entièrement configuré, le VPU peut atteindre plus de 30 fois l’accélération mesurée par les fonctions clés de MobileNets, un réseau de neurones à convolution (CNN) populaire. Comparé à la solution SIMD scalaire 128 bits bien connue, le VPU NX27V offre 4 fois plus de puissance de traitement brute par cycle, avec un avantage supplémentaire dû à la plus grande efficacité de l'émission d'instructions vectorielles.
«C’est passionnant de voir quatorze années d’investissement en R & D réunies dans un projet ambitieux», a déclaré le Dr Charlie Su. «De la microarchitecture vectorielle au sous-système mémoire, en passant par tous les écosystèmes nécessaires pour permettre à nos détenteurs de licence, quelle que soit leur ampleur et leur ampleur, les utilisateurs de RISC-V se trouvent aux frontières de ces applications embarquées.
En effet, la série 27 a considérablement élargi son sous-système de mémoire pour suivre la bande passante nécessaire au maintien du débit de calcul de la VPU, ce qui profitera à tous les clients en général, qu’ils utilisent ou non la VPU. La série 27 prend désormais en charge plusieurs accès mémoire, de sorte que les processeurs scalaire et vectoriel ne doivent pas attendre les données en cas d’absence de mémoire cache. De plus, les prélèvements en mémoire cache permettent à la mémoire de préparer les données avant les besoins du processeur, masquant ainsi les erreurs potentielles de la mémoire cache. Enfin, l'interface ACE (Andes Custom Extension) a été étendue pour permettre la personnalisation des instructions afin d'accélérer le chemin de contrôle et d'élargir le chemin de données au noyau.
Prix et disponibilité:
La version bêta du processeur 27 séries a été livrée au premier détenteur de licence Andes au début du mois de décembre 2019, avec la publication de la base de données de production au premier trimestre 2020.